To evaluate the quality and reliability of our MoodArchive dataset, we conducted a comprehensive human validation study on Amazon Mechanical Turk. Workers were tasked with comparing original web-collected alt-text with our LLaVA-generated detailed captions, assessing both content accuracy and emotional interpretation.
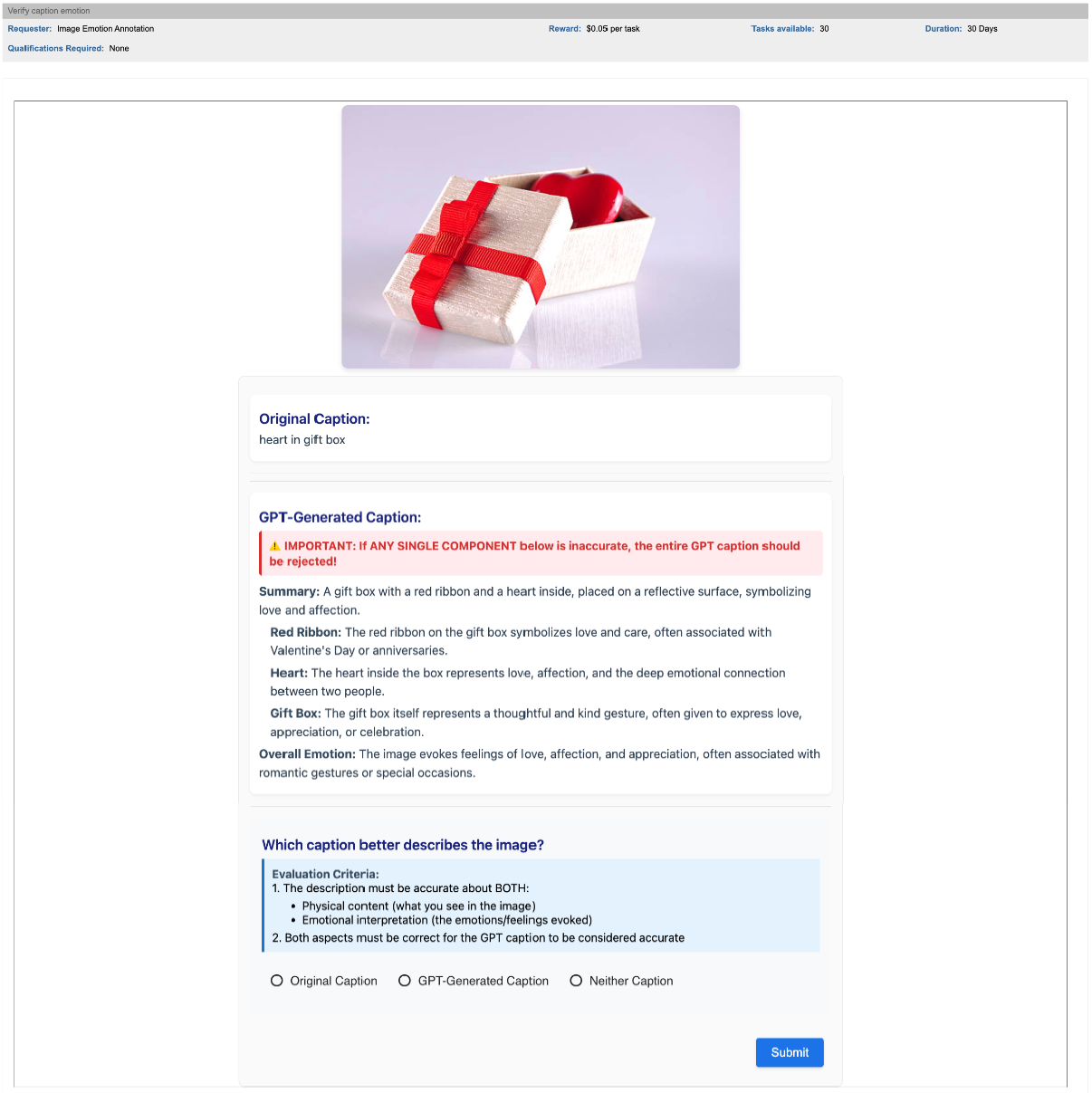
Figure 5: MTurk task instructions detailing the evaluation criteria for comparing captions.
Figure 6: The comparison interface showing image, original caption, and LLaVA-generated emotional caption.
85% of LLaVA-generated captions were selected by workers as better describing the images than the original web-collected alt-text, confirming the high quality of our automated annotation approach.
@article{,
title={},
author={},
booktitle={},
year={}
}