With MoodifyCLIP fine-tuned on MoodArchive, we propose Moodifier, a training-free, emotion-driven image editing system. The Moodifier workflow first extracts visual features fV = Encvis(V) from the source image, enabling MLLM (in our case we applied LLaVA-NeXT) to generate emotion-specific prompts PE = MLLM(fV, E) and attention maps ME that identify where modifications should occur. These outputs then guide the diffusion process to produce the emotionally transformed image.
More specifically, we adopt the non-iterative inversion approach to obtain the latent representation z. Inspired by Prompt-to-Prompt, we then manipulate the cross-attention mechanisms within the diffusion process to achieve precise emotional transformations. We operate on the key insight that cross-attention maps define the relationship between spatial image features and textual concepts.
In text-conditioned diffusion models, each diffusion step computes attention maps Mt through:
Mt = Softmax QKT √d
Equation 6: Cross-attention Map Computation
where Q = ℓQ(φ(zt)) represents visual feature queries, and K = ℓK(ψ(P)) represents textual feature keys. The cell Mi,j defines the influence of the j-th textual token on the i-th pixel. For emotional editing, we need precise control over which image regions should change and how. Our MLLM generates not only detailed prompts PE but also spatial attention maps ME that identify emotion-relevant regions.
As shown in Algorithm 1, DM (Diffusion Model) refers to a single step of the diffusion process that denoises the latent representation while computing cross-attention maps between visual and textual features. Specifically, DM(zt, PE, t) computes one denoising step from noise level t to t − 1 conditioned on prompt P, producing both the denoised latent zt−1 and the attention maps Mt. We blend attention maps from the source image with those generated for the target emotion:
M̃t = Refine(Msrc, Mtgt, ME) t ≥ τc Mtgt t < τc
Equation 7: Attention Map Blending
where τc controls attention strength. At early steps (t ≥ τc), refined attention is used to establish structure while preserving identity, whereas in later steps (t < τc), target attention maps enhance emotional details. Finally, the emotion stimulus maps ME smoothly blend source and target latents only in regions that should express the target emotion, while preserving the rest of the image.
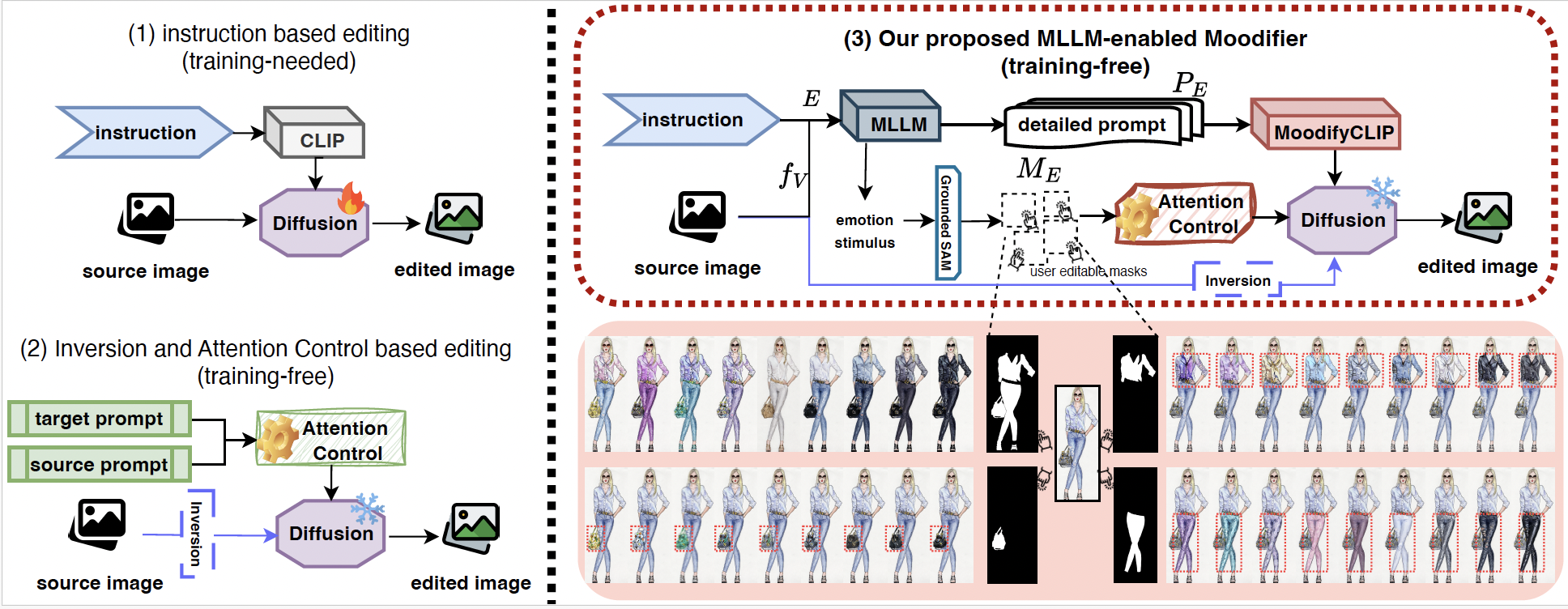
By leveraging the capabilities of MoodifyCLIP and MLLMs, our Moodifier system enables precise emotional transformations while preserving structural and semantic integrity, offering a powerful tool for creative professionals to explore emotional variations in visual content without the need for extensive manual editing or additional training.